索引
类型
- 主键:一种特殊的唯一索引,不允许有空值。
- 唯一键:索引列的值必须唯一,但允许有空值。
- 普通
- 组合(最左前缀):为了更多的提高 mysql 效率可建立组合索引,遵循“最左前缀”原则。创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。组合索引最左字段用 in 是可以用到索引的。
索引的优点
- 大大减少服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机 I/O 变为顺序 I/O
高性能的索引策略
- 独立的列:索引列不能是表达式的一部分,也不能是函数的参数
- 前缀索引:当要索引的字符列很长时,可以只索引前缀字符的方式,这样可以节约索引空间,提高索引效率。前缀长度选择,应该使得前缀索引的选择性接近于索引整个列。前缀索引需注意的是不能做
order by和group by。
- 多列索引:
- MySQL5.0 版本引入“索引合并”策略
- 优化索引顺序
- 创建全覆盖索引
索引优化实际例子
- 联合索引“隔离列”优化,将联合索引中为被查找的列添加全部可能到查询中,可以使索引得以继续使用。若此列数据量太多,则不适合此方法,需建立额外索引处理。
聚集索引
- 聚集索引:索引中键值的逻辑顺序决定了表中相应行的物理顺序(索引中的数据物理存放地址和索引的顺序是一致的)。
- 非聚集索引:索引的逻辑顺序与磁盘上的物理存储顺序不同。
Inno DB 的聚集索引规则:
- 如果一个主键被定义了,那么这个主键就是作为聚集索引
- 如果没有主键被定义,那么该表的第一个唯一非空索引被作为聚集索引
- 如果没有主键也没有合适的唯一索引,那么 innodb 内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键是一个 6 个字节的列,改列的值会随着数据的插入自增。
B-Tree 索引
MySQL 在创建表时使用这个名字,但并不是每个存储引擎实际都使用这个存储结构,如 NDB 集群存储引擎内部实际是 T-Tree;InnoDB 则使用的是 B+Tree。
每个存储引擎以不同的方式使用 B-Tree 索引,性能也各有不同。如 MyISAM 使用前缀压缩技术使索引更小,InnoDB 按照元数据格式存储;MyISAM 索引通过数据的物理位置引用被索引的行,InnDB 则根据主键引用被索引的行。
结构
B-Tree 意味着所有的值都是顺序存储的,且每个叶子页到根的距离相同。
适用情况
- 全值匹配
- 匹配最左前缀
- 匹配范围值
- 精确匹配某一列,并范围匹配另一列
- 只访问索引的查询(覆盖索引)
- ORDER BY 满足前几个条件,也可使用 B-Tree 索引
不适用情况
- 不满足最左前缀
- 不能跳过索引中的列
- 如果其中某列范围查询,则右边的列不能使用索引优化
Hash 索引
基于 hash 表实现,对所有索引列计算 hash 值,hash 索引将这些值存储起来,并且保存该 hash 值指向的数据。当 hash 碰撞时,索引会以链表方式存放多个记录到同一个 hash 条目中。在 MySQL 中只有Memory引擎支持。
适用情况
- “星型”schema,需要关联很多查找表,hash 索引非常适合查找表的需求
- 一些值较大的索引,可以通过模拟 hash 索引的方式实现,比如 url 存储,可以设置一列存储 url 的 hash,查找时这样进行
SELECT * FROM url WHERE url = 'www.mysql.com' AND url_crc = CRC32('www.mysql.com')。注意,此时不要使用 SHA1()MD5() 作为 hash 函数,因为其生产的字符串很长,浪费空间。
不适用情况
- hash 索引只包含 hash 值和行指针,不存字段值,所以无法避免行读取。不过访问内存中的行速度很快,大部分时候这种行为对性能影响不明显
- hash 索引不包含顺序,无法排序
- 不支持索引中的列的部分查找
- 只支持等值比较,包括
=IN()<=> ,也不支持范围查找
- 当 hash 冲突较多时,查询和维护索引的性能下降
物理结构
共享池优化
绑定变量,节省解析时间
排查方式:
- awr 报表
- trace
overall totals for all recursive statements
反例:
- 影响 SQL 索引选择
select count(*) from t where id < 990; -- 全表
select count(*) from t where id < 10; -- 索引
select count(*) from t where id < :id; -- 不做优化,一直使用索引
日志优化
logical : database --> table space --> segment --> extent --> data block
physical: data file --> OS block
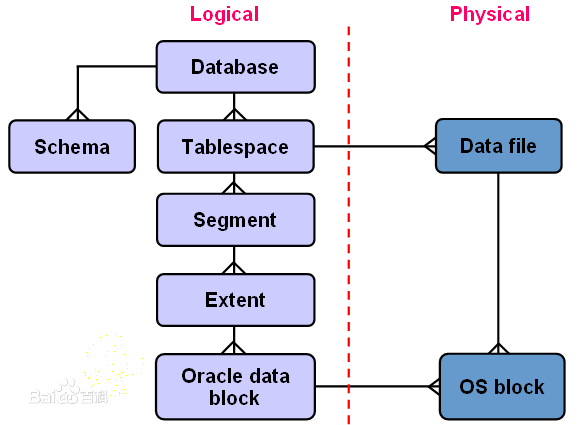
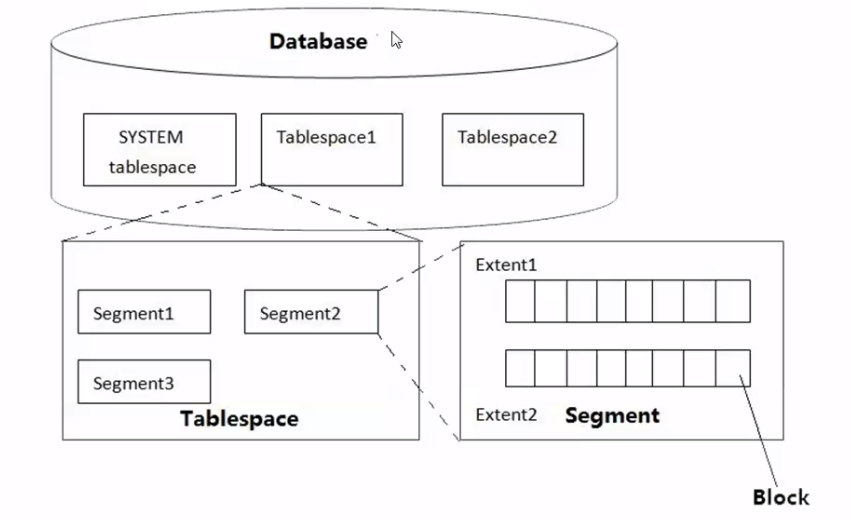
最小单位 block
- 数据块头(类型,地址,归属 segment)
- 表目录(某行数据插入到块中,该行数据所在表的信息)
- 行目录(行地址)
- 可用空间(剩余空间;若是表或索引块,会存放事物条目)
- 行数据区(行或索引的信息)
一个 block 能装多少行?
各种开销导致,每行最小长度大致是 11 字节,例如,一个 8k 块理论上最多存储不超过 8096/11 行
行迁移
- 成因:当行 update 时,若 update 更新的行大于数据库的 pctfree(可用空间)就需要申请新的块,从而形成迁移
- 后果:导致应用需要更多的快,性能下降
- 预防:pctfree 调大;块调大
- 检查:
analyze table <table name> validate structure cascade into chained_rows
行链接
- 成因:如果我们往数据库中插入(INSERT)一行数据,这行数据很大,以至于一个数据块存不下一整行,Oracle 就会把一行数据分作几段存在几个数据块中,这个过程叫行链接(Row Chaining)
优化点
- block 空间越大,逻辑读越少
- block 空间越大,并发争抢更激烈
段(segment)
建表产生表段,建索引产生索引段,空间申请以区(extend)为单位,最小单位是块(block)。extend 以若干个连续的 block 组成。随着记录变多,segment 包含的 extents 和 blocks 也增多。
- 成因:delete 无法降低高水平位,表扫描依然需要大量的逻辑读,并且表的大小依然不变。move 能减低高水平位,逻辑读和表大小也会减小。
- 检查:blocks 和 row nums 不成比例;全表扫描时间异常
优化点
- 利用分区表优化查询,因为分区可以只扫描特定的段,性能更好
表设计
优化数据类型
MySQL 数据字段选取原则
- 更小的更好
- 通常来说更小更快,占用的资源更少
- 需要正确评估字段大小,在 schema 增加数据类型的范围是是很耗时和痛苦的操作
- 简单就好
- 简单的数据类型操作通常需要更少的 CPU 周期
- 例如,用内建日期类型存储时间,而不是字符串;不用整型存储 ip
- 尽量避免 NULL
- NULL 列使存储、索引和比较都更为复杂
- NULL 列存储需要更多空间,需要特殊处理
- NULL 列为索引时,每个索引记录都需要记录一个额外的字节
MySQL 数据类型
- 整数
- TINYINT(8), SMALLINT(16), MEDIUMINT(24), INT(32), BIGINT(64)
- 可选有符号与无符合,无符号多存储一倍范围
- 注意,INT(10)中的 10 只表示宽度
- 实数
- FLOAT(4), DOUBLE(8), DECIMAL
- 尽量只在对小数进行精确计算时,才使用 DECIMAL;在数据量较大时使用 BIGINT 代替,可提高效率
- DECIMAL(18,9)表示,一共 18 位数字,小数部分为 9 位
- 字符串
- VARCHAR, CHAR, BINARY, VARBINARY
- VARCHAR 是可变长的,更省空间;但 Update 时,字段长度变化,可能导致页空间不够存储新字段值的情况
- VARCHAR 使用场景:最大长度比平均长度大很多;列更新较少;复杂编码(如 UTF-8)每个字符使用不同的字符数
- CHAR 使用场景:很短的字符串,或长度都相近
- 日期时间
- DATETIME:保存大范围的值(1001 ~ 9999),精度到秒,与时区无关,8 字节
- TIMESTAMP:1970 ~ 2038,存 1970/1/1 开始的秒数,4 字节,依赖与时区。可以自动更新,默认为 NOT NULL
- 除特殊行为外,尽量使用 timestamp,因为其更高效
- BLOB 和 TEXT
- MySQL 会把 BLOB 和 TEXT 当作独立的对象处理,当值太大时会使用专门的外部区域存储,行内只存储指针
- 排序只针对
max_sort_length字节而不是整个列
MySQL 标识符选择(identifier)
标识符更有可能和其他值比较(例如关联操作),或者通过标识符找寻其他列。标识符也可能作为其他表的外键,要确保在所有关联表中都使用同样的类型,混用会导致性能问题,或者隐式转换中难以发现的错误。
整数通常是最好的选择,因为它们很快,且可以使用 AUTO_INCREMENT。
如果可能,应该避免使用字符串类型作为标识符,很消耗空间,且通常比数字类型慢。尤其是使用 MyISAM 时,因为 MyISAM 会对字符串做压缩索引,会导致查询慢得多。
用完全随机生成的值作为标识符也会导致性能问题。INSERT 时由于值会插入到不同的位置,导致页分裂、磁盘随机访问,以及对于聚簇存储引起产生聚簇索引碎片。SELECT 语句也会变慢,因为可能逻辑上相近的数据分布在磁盘和内存不同的地方。还会导致缓存的效果变差,因为缓存的访问局部性原理失效(如果整个数据集都很“热”,则缓存部分没有好处;如果工作集比内存大,缓存将会有很多刷新和不命中)
如果用 UUID,应移除-。UUID 虽然分布也不均匀,但还是有一定顺序。但还是不如递增整数好。
MySQL schema 设计中的陷阱
- 太多列
- 太多的关联:如 EAV 设计,MySQL 限制了每个关联操作最多只能有 61 张表,通常情况下单个查询最好控制在 12 个表以内。
- 全能枚举:如 country enum(‘’,’0’,’1’,’2’,’3’….)
- 变相枚举:如 is_default enum(‘Y’, ‘N’)
- Not invent here 的 null:用其他形式的特定值表示 null,造成不必要的复杂运算
数据库设计范式
范式的优点
- 更新快:范式化较好的数据库,没有或者很少重复数据,所以修改更少的数据
- 表更小,更好的放在内存中,执行操作更快
- 检索时需要更少的 DISTINCT 或者 GROUP BY 语句
范式的缺点
- 关联操作变多,可能导致索引策略无效(列如,范式化可能将列放在不同的表中,而这些列如果在同一个表中本可以属于同一个索引)
反范式的优点
- 可以避免关联:不需关联时最坏情况(没有索引)也是全表扫描,当数据比内存大时这比关联快很多,因为避免了随机 I/O
- 可以创建更有效的索引策略
混用范式和反范式化
- 最常见的反范式化数据的方式是复制或缓存,在不同的表中存储相同的特定列
- 缓存衍生值也是有用的,如缓存一个用户参加了多少活动,每当用户加入一个新活动时更新这个值
分区表
分区表可以包括多个分区, 每个分区都是一个独立的段( SEGMENT),可以存放到不同的表空间中 。查询时可以通过查询表来访问各个分区中的数据,也可以通过在查询时直接指定分区的方法来进行查询
分区表有四种方式:范围 R(月,天),列表 L(地区,区号),哈希 H(负载均衡),组合:11g 前(RL,RH);11g 后(RR,LL,LH,LR)。
优点:
- 由于将数据分散到各个分区中,减少了数据损坏的可能性;
- 可以对单独的分区进行备份和恢复;
- 可以将分区映射到不同的物理磁盘上,来分散 IO;
- 提高可管理性、可用性和性能。
全局临时表
如果数据是临时的,也就是说用完即抛,需要频繁执行删除操作(删除操作会造成大量日志写入,占用服务)
缓存表与汇总表
有时可以通过在表中保存衍生数据提升性能。有时也需要创建一张汇总表或缓存表(特别是为满足检索的需求时)。
- 汇总表:例如,将一些有意义的统计信息,提前计算好,避免过多的数据查询
- 缓存表:例如,可能需要很多不同的索引组合来加速各类型的查询,这些矛盾的需求可以通过创建一张只包含主表部分列的缓存表。一个小技巧是可以使用不同的存储引擎。
其他设计优化
计数器表
提高计数器表的并发,可以设置多个行,每次更新时随机更新一行,算总和时再合并。这些行可以预先生成,或者使用ON DUPLICATE KEY UPDATE,如果担心行数太多,也可以定时合并。
加快 MySQL ALTER TABLE速度
MySQL 查询优化
衡量查询的三个指标:
- 响应时间:最重要的指标,但要记住是表面的值。因为它是服务时间+排队时间,可能受当时服务器情况影响
- 扫描的行数:非常有用,但不够完美。因为并不是访问所有行的代价都一致
- 返回的行数
优化数据访问
对低效查询,可以通过两个步骤分析:
- 确认是否在检索大量超过需要的数据,这通常意味着访问了太多的行,但有时候也可能是访问了太多的列
- 多余的行,如只需要前10行,但查了100行
- 多余的列,如关联查询时返回全部列、总是查询全部列
- 重复查询相同的数据,可使用缓存优化
- 确认 MySQL 服务层是否在分析大量超过需要的数据行
- 使用覆盖索引,把所有需要的行都放在索引中,这样无需回表
- 改变表结构,如汇总表
- 重新SQL
重构查询方式
- 复杂查询还是简单查询:当性能足够的时候可以先用复杂,若发现明显性能问题可优化为简单查询
- 切分查询:如删除大量数据时,可以多次执行删除少量数据,直到删除完所有数据
- 分解关联查询
- 让缓存更高效
- 减少锁竞争
- 减少对数据库层的依赖,数据库拆分时更容易,更容易做到高性能和可拓展
- 查询有可能会提升,如
in替代关联查询,从随机读变为顺序读
- 减少冗余记录的查询
优化点总结
减少全表扫描
- 减少不必要的方法调用,缩小调用方法的次数
- 只取需要的列(只用索引无需回表;只用索引连表速度变快)
- 索引优化
其他
- 批操作能提升性能
- 使用绑定变量,减少硬解析次数
- 功能性表选取,临时表或分段表
- 合理设置块,区,表空间大小
comments powered by